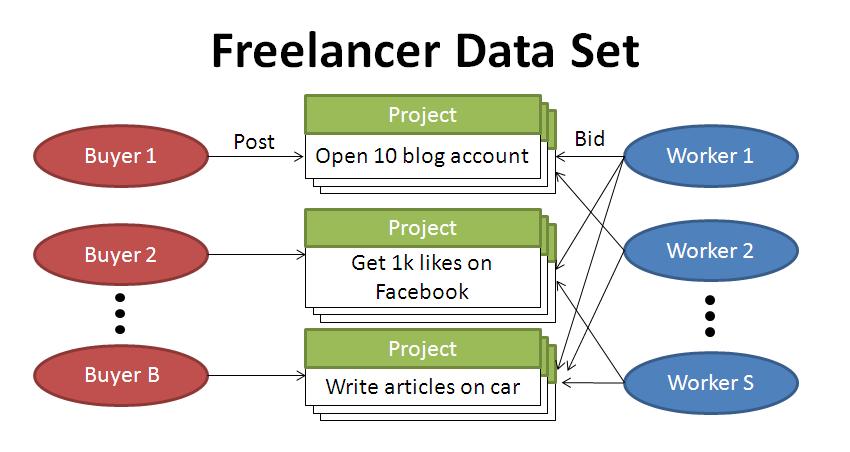
Crowdsourcing is thriving as a low-cost outsourcing mechanism. Unfortunately, many Web service abusers are using crowdsourcing to mount attacks on popular Web services such as Google, Yahoo and Facebook. Thus, crowdsourcing sites and Web service providers need ways to control the influx of abuse-related jobs. In this project, we use topic modeling to identify abuse-related job postings on Freelancer.com, a popular site for crowdsourcing.
In our AISec-11 paper , we explored the use of latent Dirichlet allocation (LDA) on our Freelancer data set. Our analysis suggests that LDA can provide an effective and largely automated tool for monitoring abuse jobs.
Going forward, we are applying more sophisticated topic models to the data set. Please feel free to check back for updates. The Freelancer data set is available in the Data Set section.